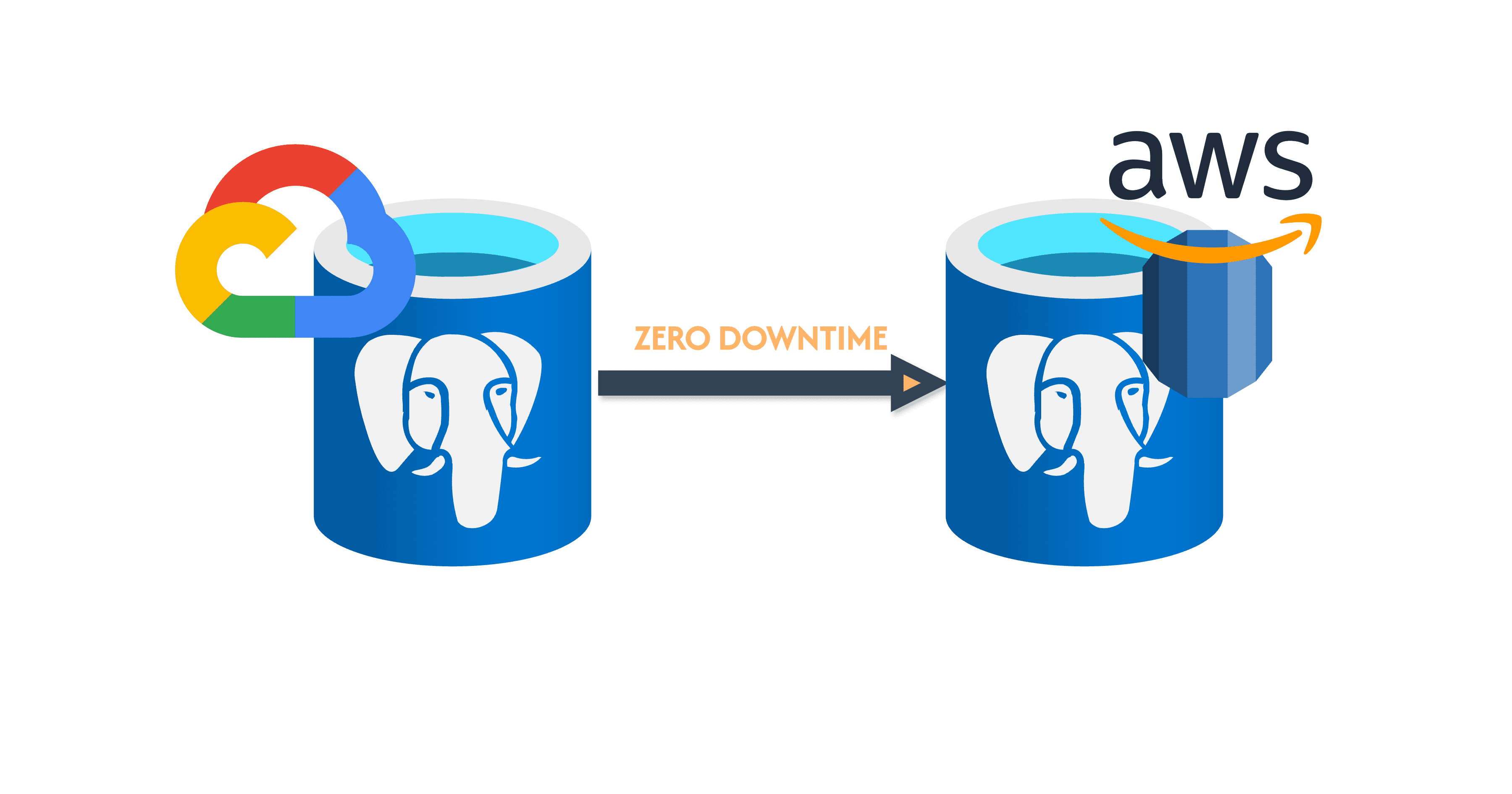
Zero Downtime Postgres Database Migration from GCP to AWS RDS
In 2023, I was working at a company where we were running our Elixir backend on Gigalixir.
Gigalixir is a PaaS similar to Heroku that at the time we were using provided its managed database service for Postgres via GCP (Google Cloud Platform). I found it troublesome since it was a bit of a black-box with limited scaling and observability. I motivated this migration since we needed to be able to scale the DB more granularly, monitor disk, CPU, memory and disk usage and better backups and restores.
A zero downtime migration strategy was ideal since more 9s = happier users + happier engineers. I decided to use Postgres logical replication which allows you to make the source database a publisher and the migration target a subscriber to synchronise data between them. In our case, the GCP DB would be the publisher whereas the AWS one would be the subscriber.
Strategy
This was the general strategy I came up with:
Replicate the schema from GCP onto a new RDS DB instance
Enable logical replication on RDS and sync existing data then continue ongoing replication
Cutover the application to the GCP database
I found that AWS RDS prevents creation of a subscriber. They have an rds_replication role present on the database but it seemed artificially limited and couldn’t actually create subscriptions, forcing one to go through their paid service AWS Database Migration Service (DMS) which uses logical replication under the hood. So this service is what I used.
Here's a guide of how I did it:
Steps
I. Prep the GCP source database
Ensure the
wal_levelis set tologicalon and that pglogical, which is the extension that helps with this replication strategy, is installed.Set
cloudsql.logical_decodingandcloudsql.enable_pglogicalflags to on and reboot the DB which could make it unavailable for a few minutes but should take seconds on average.SHOW wal_level; -- should return logical CREATE EXTENSION pglogical; SELECT * FROM pg_catalog.pg_extension WHERE extname = 'pglogical'; -- should return row showing pglogical is installedCreate replication user which AWS DMS will use to login and grant them the appropriate roles:
CREATE USER repl_user_from_aws WITH REPLICATION IN ROLE cloudsqlsuperuser LOGIN PASSWORD '<generated password>'; -- permit AWS' access to pglogical tables GRANT USAGE ON SCHEMA pglogical TO repl_user_from_aws; GRANT SELECT ON ALL TABLES IN SCHEMA pglogical TO repl_user_from_aws; -- permit AWS' read access to all our tables GRANT USAGE ON SCHEMA public TO repl_user_from_aws; GRANT SELECT ON ALL TABLES IN SCHEMA public TO repl_user_from_aws;
II. Prep the AWS RDS target database
Set the following DB parameters in the parameter group to switch on logical replication
rds.logical_replication = 1 session_replication_role = replicaSetup the following PG extensions:
CREATE EXTENSION IF NOT EXISTS pg_stat_statements; CREATE EXTENSION IF NOT EXISTS pglogical;Fetch the DB schema from the source database and create it on the target RDS DB.
pg_dump $GCP_DB_ADMIN --schema-only --no-privileges --no-subscriptions --no-publications -Fd -f ./db_schema pg_restore -Fd -v -n public --single-transaction -s --no-privileges -h <target-db-host> -U <target-db-username> -p 5432 -d <target-db-name> ./db_schema # pg_restore: connecting to database for restore # Password: # pg_restore: creating TABLE "public.****" # pg_restore: creating TABLE "public.****" # pg_restore: creating TABLE "public.****" # …Validate table schema equivalency between GCP DB and AWS RDS DB
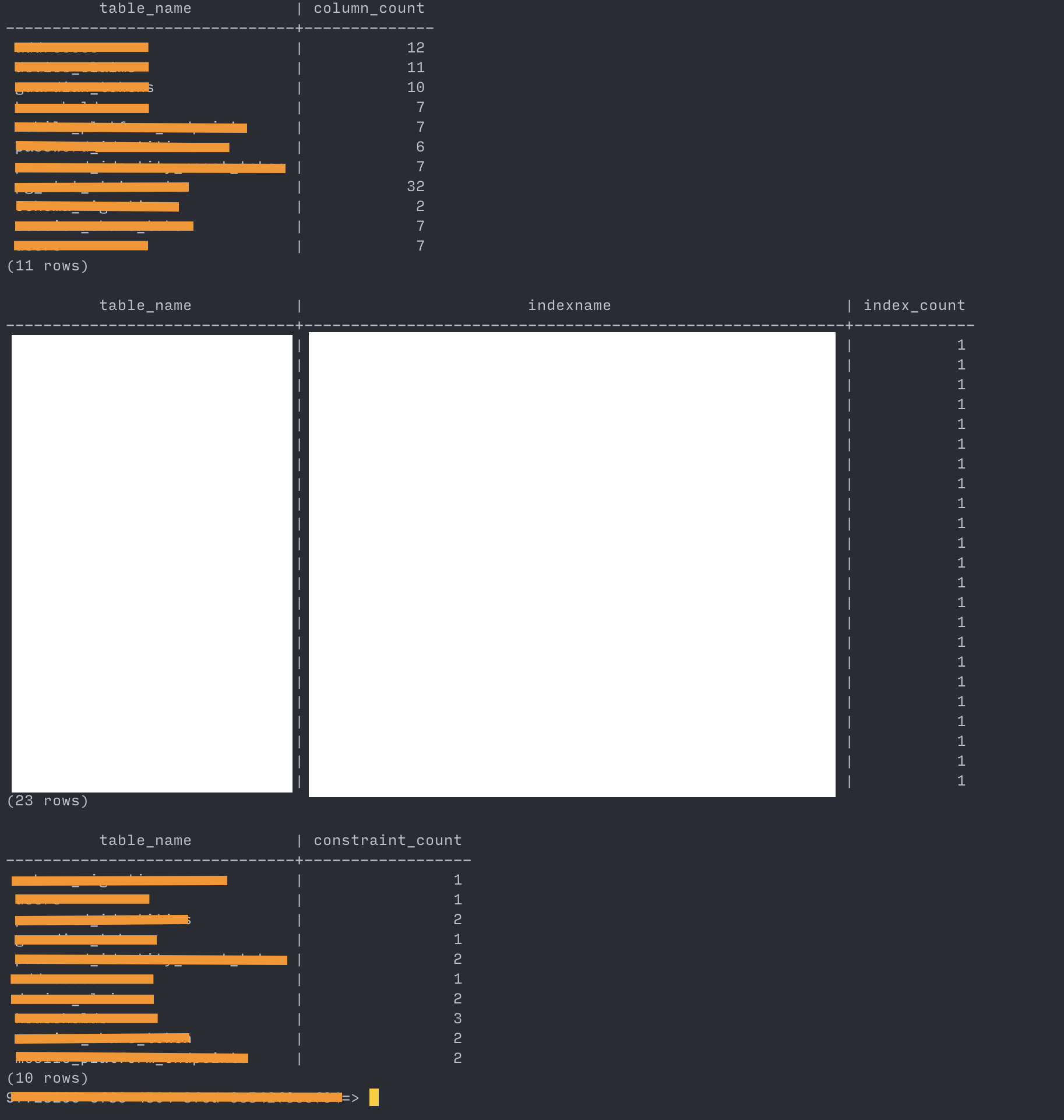
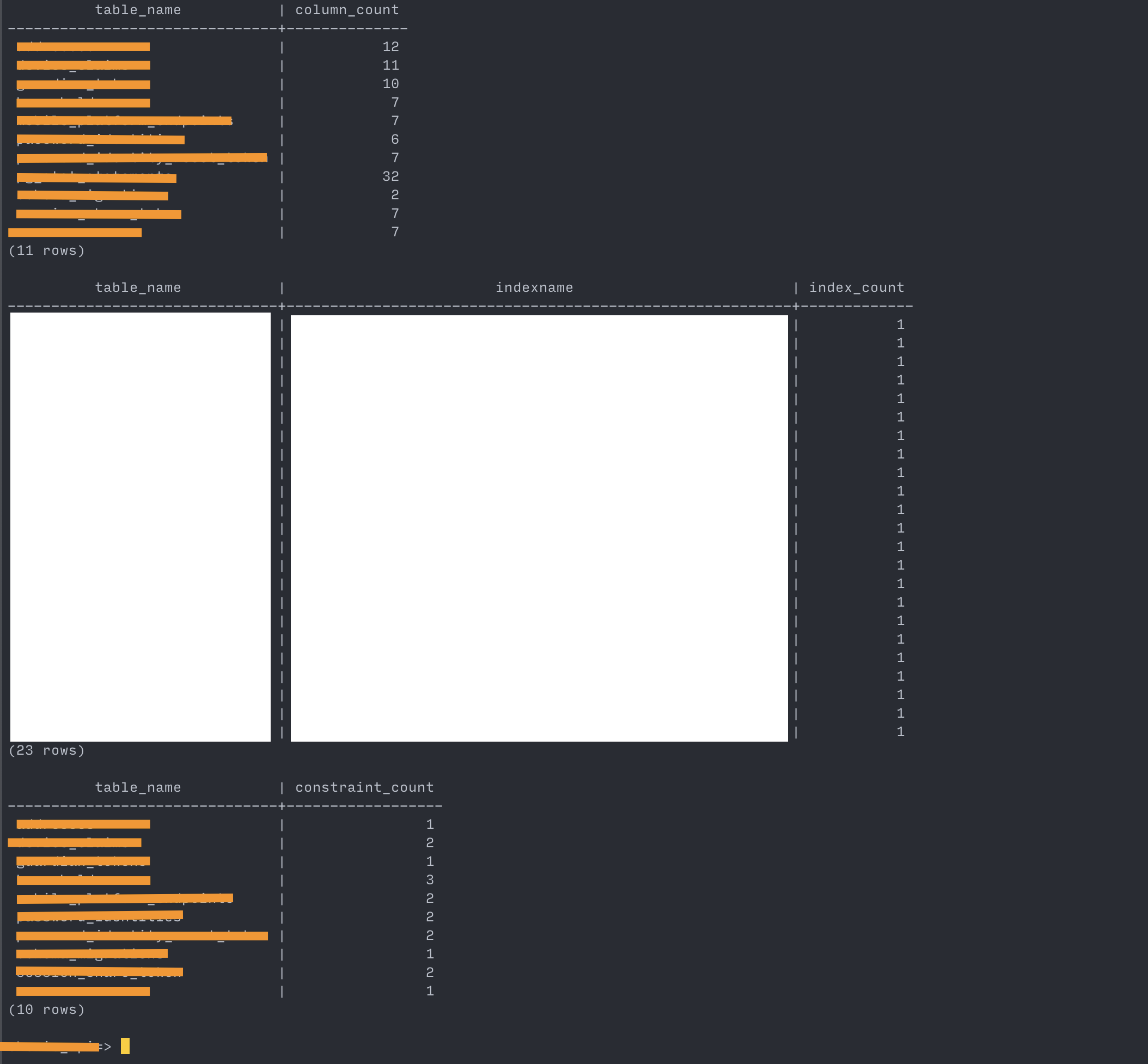
--- Show columns, indices and constraints counts ---- column count SELECT table_name, count(column_name) AS column_count FROM information_schema.columns WHERE table_schema = 'public' GROUP BY table_name ORDER BY table_name; ---- index count SELECT tablename AS table_name, indexname, COUNT(indexname) AS index_count FROM pg_indexes WHERE schemaname = 'public' GROUP BY indexname, tablename ORDER BY tablename; ---- constraint count SELECT conrelid::regclass AS table_name, COUNT(conname) AS constraint_count FROM pg_constraint WHERE connamespace = (SELECT oid FROM pg_namespace WHERE nspname = 'public') GROUP BY table_name ORDER BY table_name;
III. Initialize migration with AWS DMS
Via the AWS console, create the DMS replication instance with the following settings. Make sure to use the same VPC as the target RDS DB if one exists, otherwise place it in the default VPC.
name: staging-migrator size: dms.t3.medium storage: 5 GiB vpc: vpc-xxxxxx subnet group: default high availability: prod (for prod migration), dev for staging migration publicly accessible: true⚠Setting it to bepublicly accessiblemakes your RDS database visible to the internet. Since AWS and GCP are separate cloud providers, this is the easiest way to allow them to connect barring setting up some network peering. Consider that if your security is necessary but for most usecases, enforcing SSL and using a secure password might be enough.Create the source endpoint using the GCP database's credentials.
name: prod-gcp-db engine: PostgreSQL server name: <Gigalixir DB host> port: 5432 username: repl_user_from_aws password: <repl_user_from_aws password> ssl mode: require database name: db name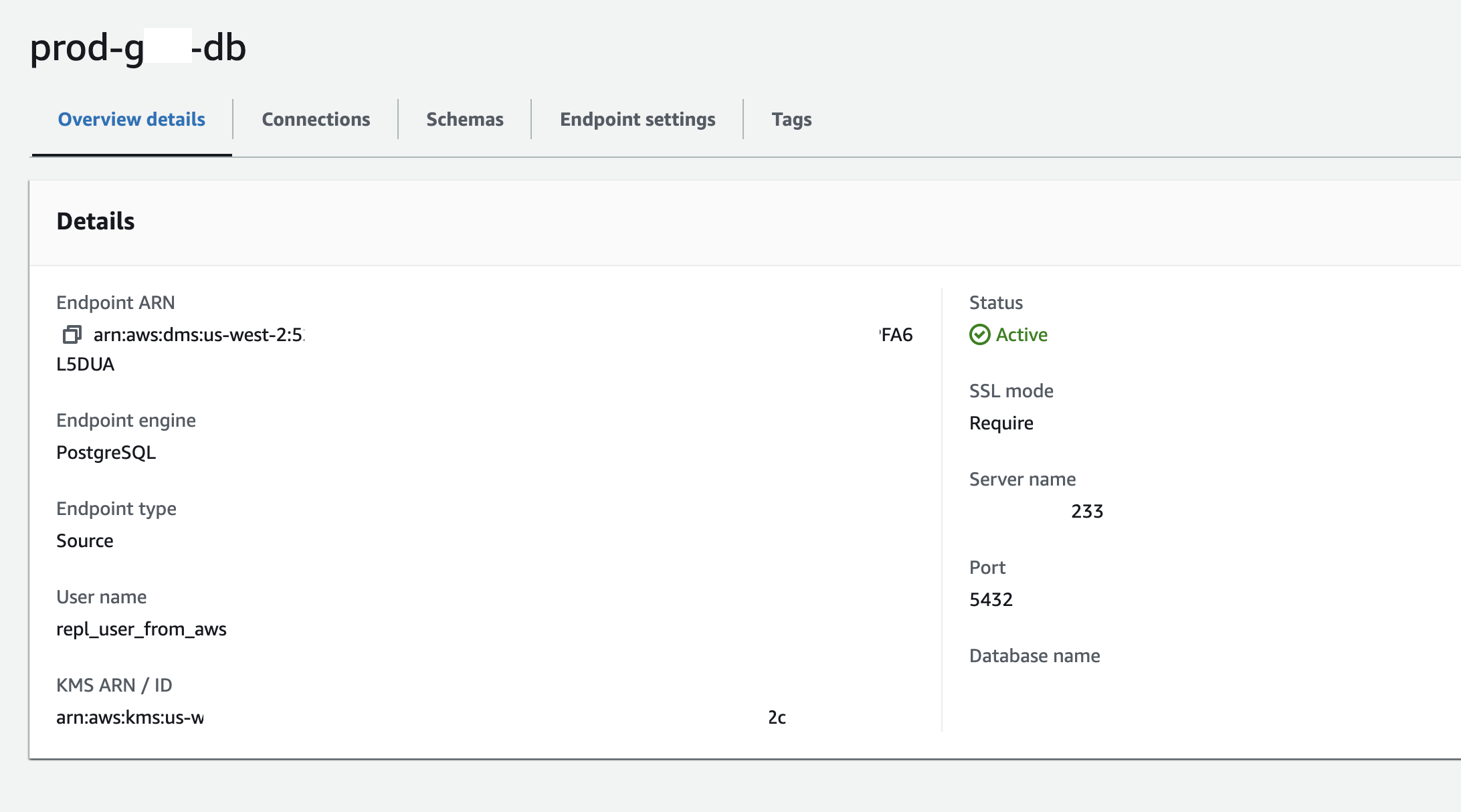
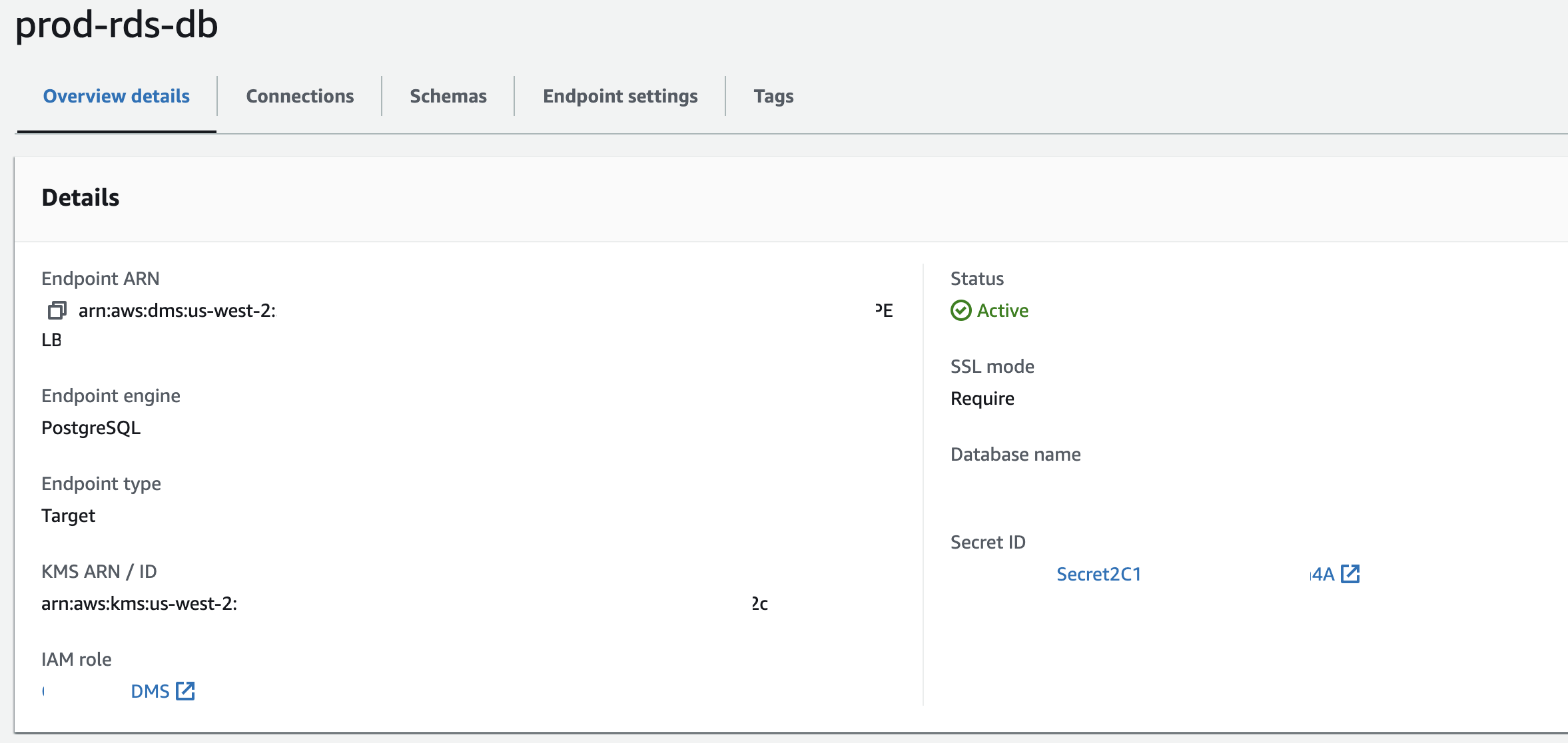
Create the target endpoint using RDS DB credentials. You can use the raw credentials or optionally create and use an AWS SecretsManager secret since your DB is on RDS like I did.
Create a migration task using the source and target endpoints from the above steps setting migration type as
Migrate existing data and replicate ongoing changes.💡Enable Cloudwatch logging so it's easier to debug in case it halts or there are conflicts.Specify the following task settings and table mapping rules in this gist.
Once it starts, it will perform a full load before proceeding to ongoing replication where changes will stream from GCP as they happen. Once it is in ongoing replication it's move to the cutover stage.
IV. Cutover
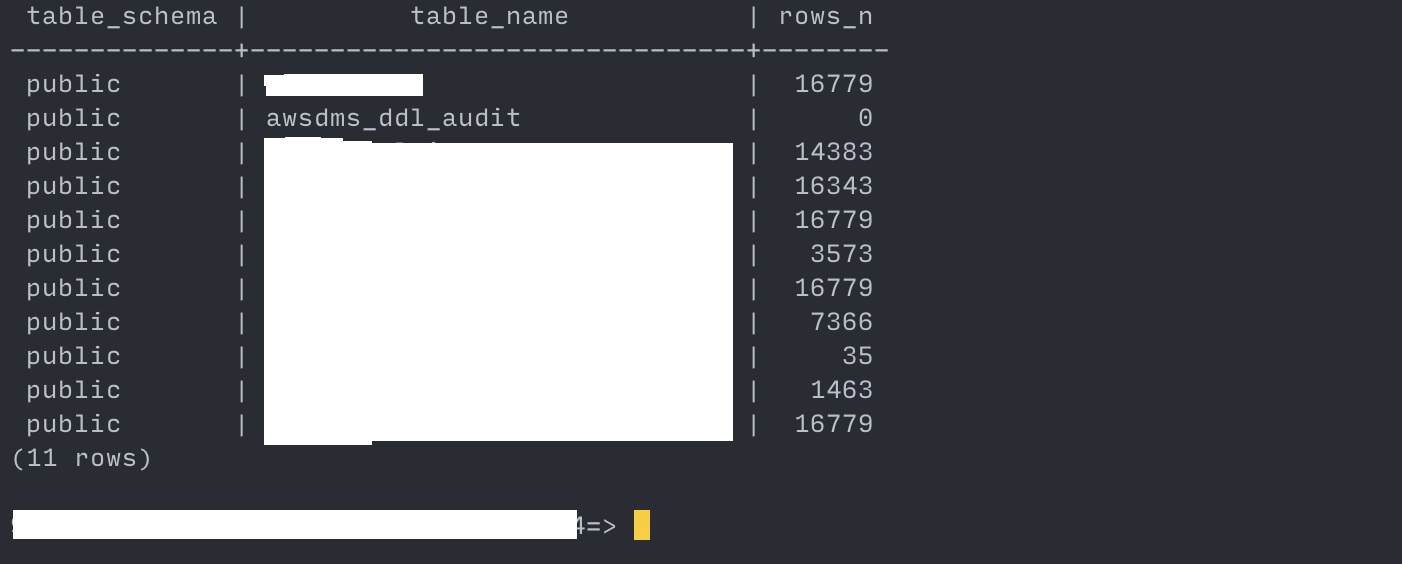
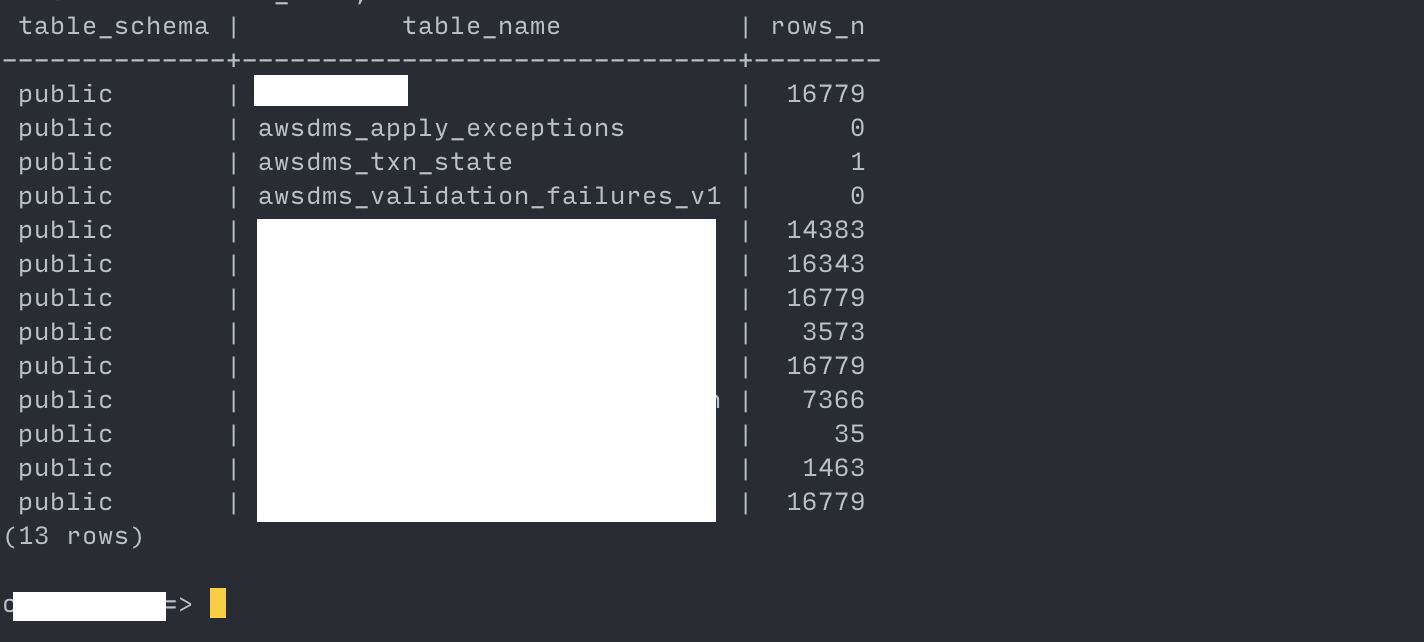
Once the full load of all the tables is completed and it switches to ongoing replication, validate that the target RDS DB tables match the source:
--- show the row counts for each table. --- https://stackoverflow.com/a/2611745/7558991 WITH tbl AS (SELECT table_schema, TABLE_NAME FROM information_schema.tables WHERE TABLE_NAME not like 'pg_%' AND table_schema in ('public')) SELECT table_schema, TABLE_NAME, (xpath('/row/c/text()', query_to_xml(format('select count(*) as c from %I.%I', table_schema, TABLE_NAME), FALSE, TRUE, '')))[1]::text::int AS rows_n FROM tbl ORDER BY TABLE_NAME;Proceed to cutting over the application only if the row counts match.
Switch over your application configs to use the new DB connection credentials
postgres://<user>:<password>@<host>:5432/my_app.Once your application is switched over to the RDS DB, stop the DMS migration task.
Celebrate (cautiously).
V. Cleanup
Drop the replication user and AWS DMS objects from your GCP database
GRANT ALL on awsdms_ddl_audit TO public; GRANT ALL on awsdms_ddl_audit_c_key_seq TO public; ALTER TABLE awsdms_ddl_audit OWNER TO gigalixir_admin; REVOKE ALL ON ALL TABLES IN SCHEMA public, pglogical FROM repl_user_from_aws; REVOKE ALL ON SCHEMA public, pglogical FROM repl_user_from_aws; DROP FUNCTION awsdms_intercept_ddl CASCADE; DROP USER repl_user_from_aws; DROP TABLE awsdms_ddl_audit CASCADE;Revert the RDS DB parameters:
rds.logical_replication = 0 session_replication_role = originRemove the DMS replication instance and source & target endpoints.
Evaluation and validation examples
Here’s how some of the validation commands output looked like for me
Confirming schema equivalency between source and target
source:
target:
Row counts after migration is complete
source:
target:
Conclusion
That's how I did it. Let me know your thoughts and alternative approaches you might have in mind.